
Scaling Databases: Sharding
Basic Concepts
In sharding, we distribute the data across many database servers. There will be one or more routing servers which routes the queries to the appropriate database server. The simplest way to do this is to query all the database servers, merge their results and return it to the application. This is called broadcast or scatter-gather approach.
But downside of this approach is that it must wait until all database servers have responded. Network latency makes it slow. A better approach will be to connect directly to the server which has the data related to that particular query. This way we will reduce the load, and response will be faster. But how does router know which database to query?
To make this happen, router must be able to determine the database just by looking at the query. Query must contain some sort of identifier, and also the data on databases must be distributed in some particular order. To solve this problem, we use sharding key.
Based on this sharding key, router will immediately know where to send this query, instead of asking all database servers. However, selecting a effective sharding key requires careful consideration of several factors.
Goal of shard key
We want to choose shard key in such a way data is distributed uniformly across shards. Uniform distribution of data is necessary otherwise one shard will end up serving majority of requests thus becoming bottleneck.
How to choose sharding key?
Let’s take an example of tweets database, I assume this is how a simple tweet looks like
1{ 2 tweet_id: bigint; 3 content: string; 4 has_media: boolean; 5 origin_country: string; 6 media_link: string; 7}
Although I have represented this as JSON, it can be easily represented as table also. Out of the above fields in tweet, which one should be a shard key? Turns out there are a couple of parameters to consider before choosing a shard key. Let's discuss those in detail.
Based on cardinality
Cardinality means measure of unique value in a dataset. For example, there can be many unique values for field content so it has high cardinality whereas has_media field can either have true or false thus having low cardinality.
Higher cardinality means we can have bigger distribution range of data thus can add more servers if needed. But low cardinality means that we can’t have a lot of servers, thus reducing our ability to add more machines. Let's examine why this is important.
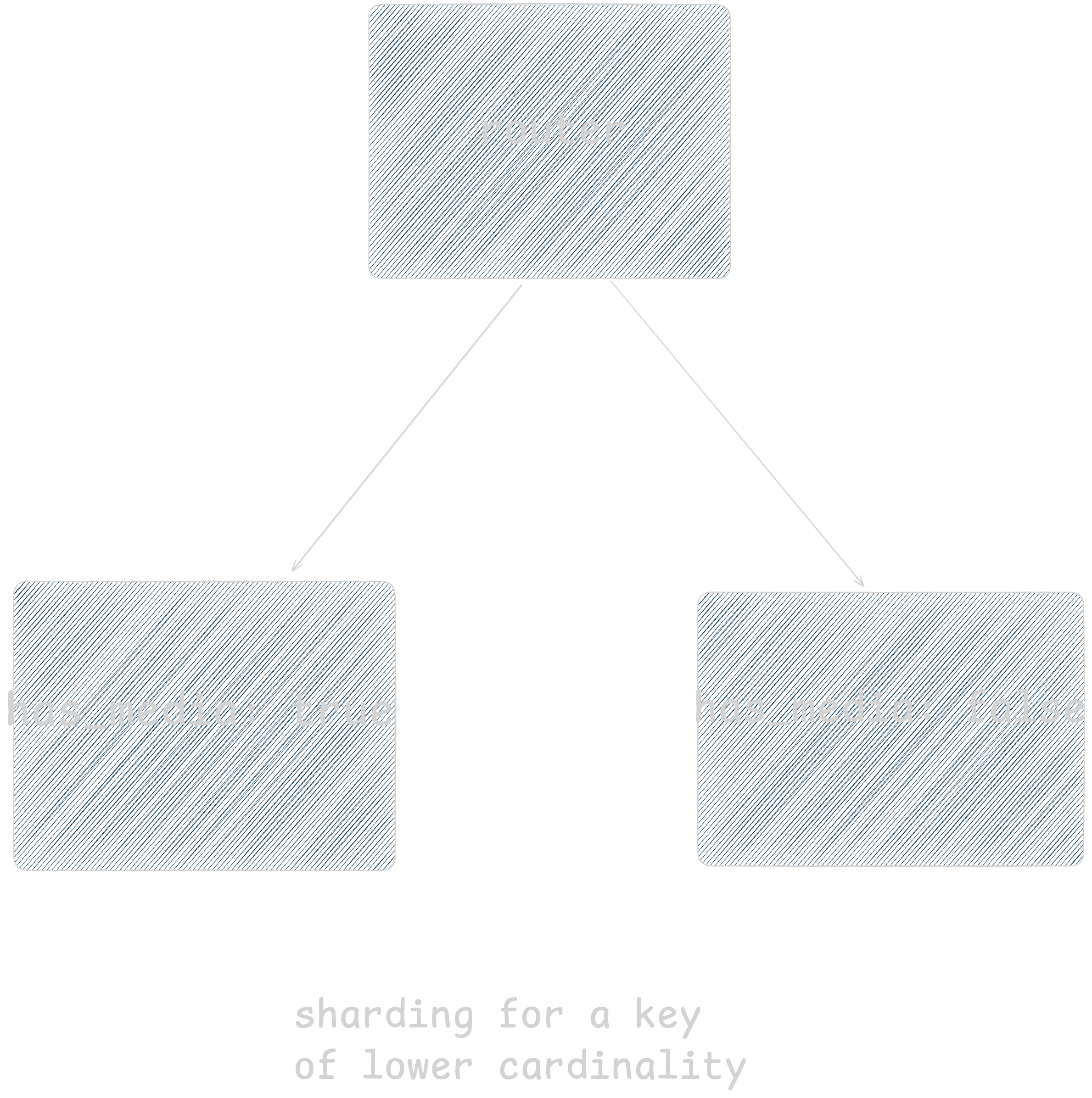
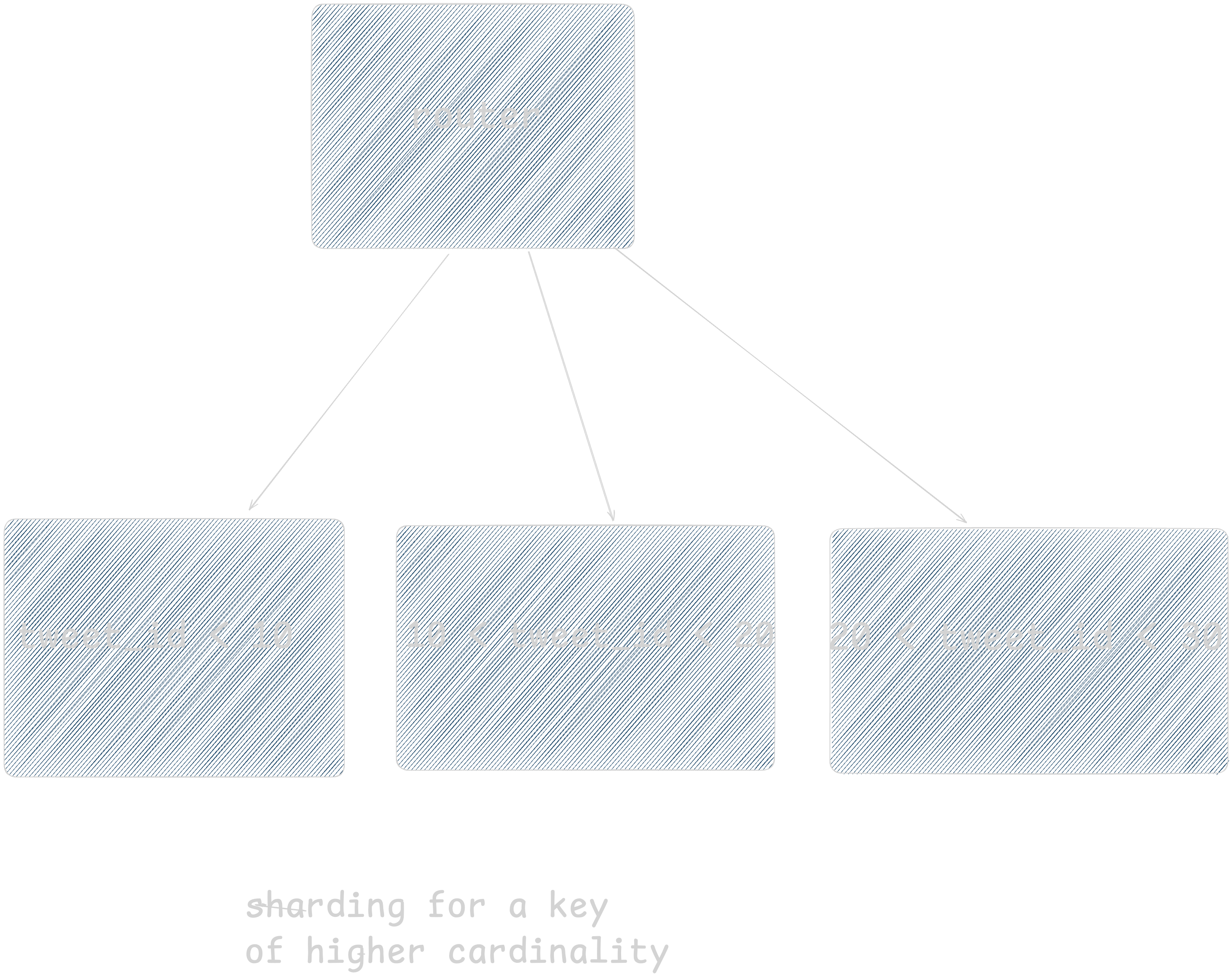
As is evident by above diagrams that higher cardinality means more independence in distributing keys across servers. So cardinality should be reasonably high.
Based on frequency
Beyond cardinality another crucial factor is to consider frequency of distribution of values of the key. If some values occur more than others, then the distribution of data will be skewed, and one shard will become larger than others. For example, if most of the tweets originates from a certain country, then choosing origin_country as shard key will make that country’s shard become larger compared to others.
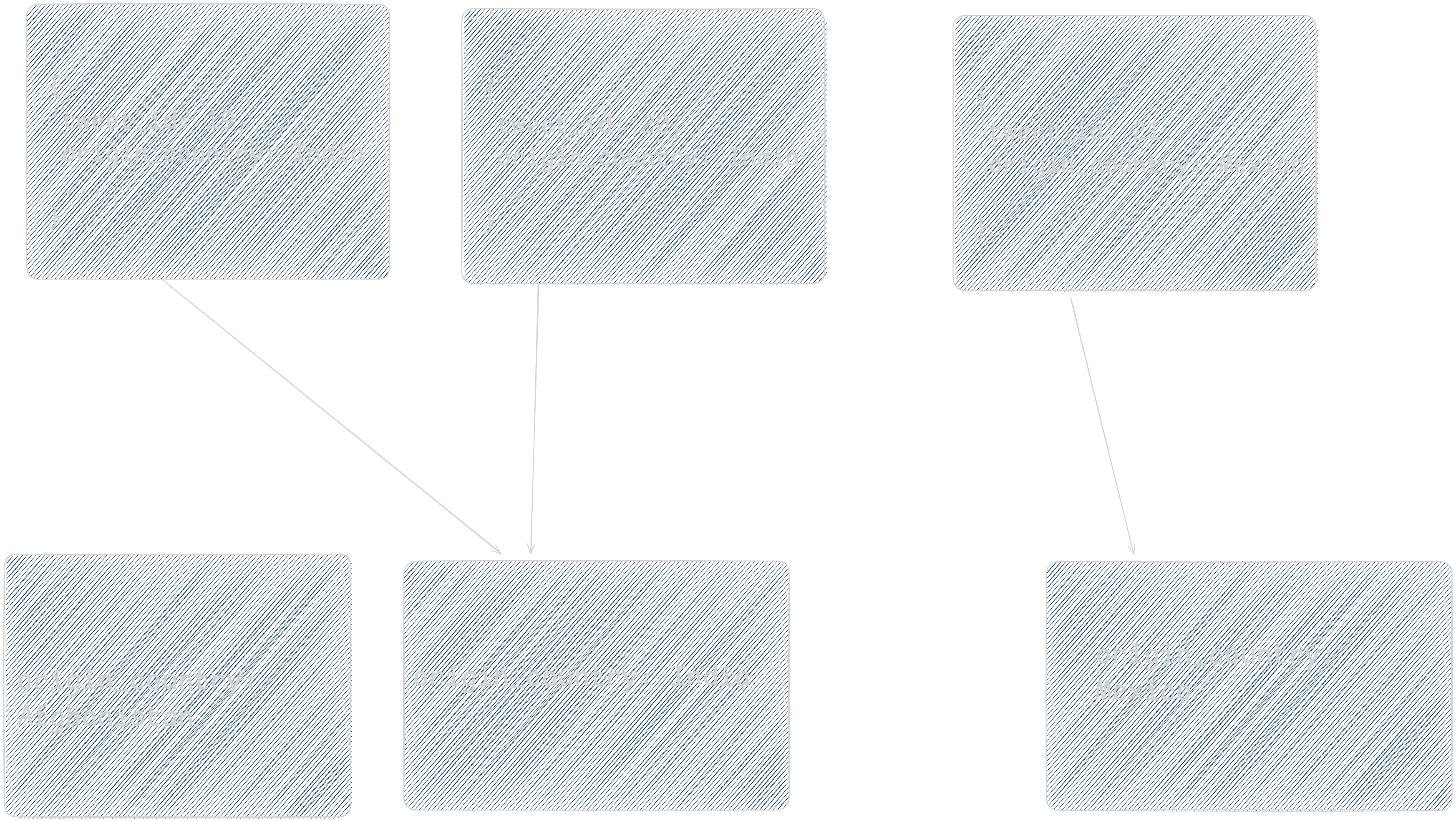
As shown in above diagram, most of our tweets have origin_country as “India” so if we choose origin_country as shard, then shard with India’s data will have more data compared to others. So we should choose key which has uniform or near uniform distribution of frequency of its values.
Based on rate of change in values
There are always shards which hold the minimum and maximum key data. If values are monotonically increasing or decreasing then it is possible for majority of them all to end up on same shard. For example, tweet_id is generated based on an auto incrementing counter, then its values are monotonically increasing.
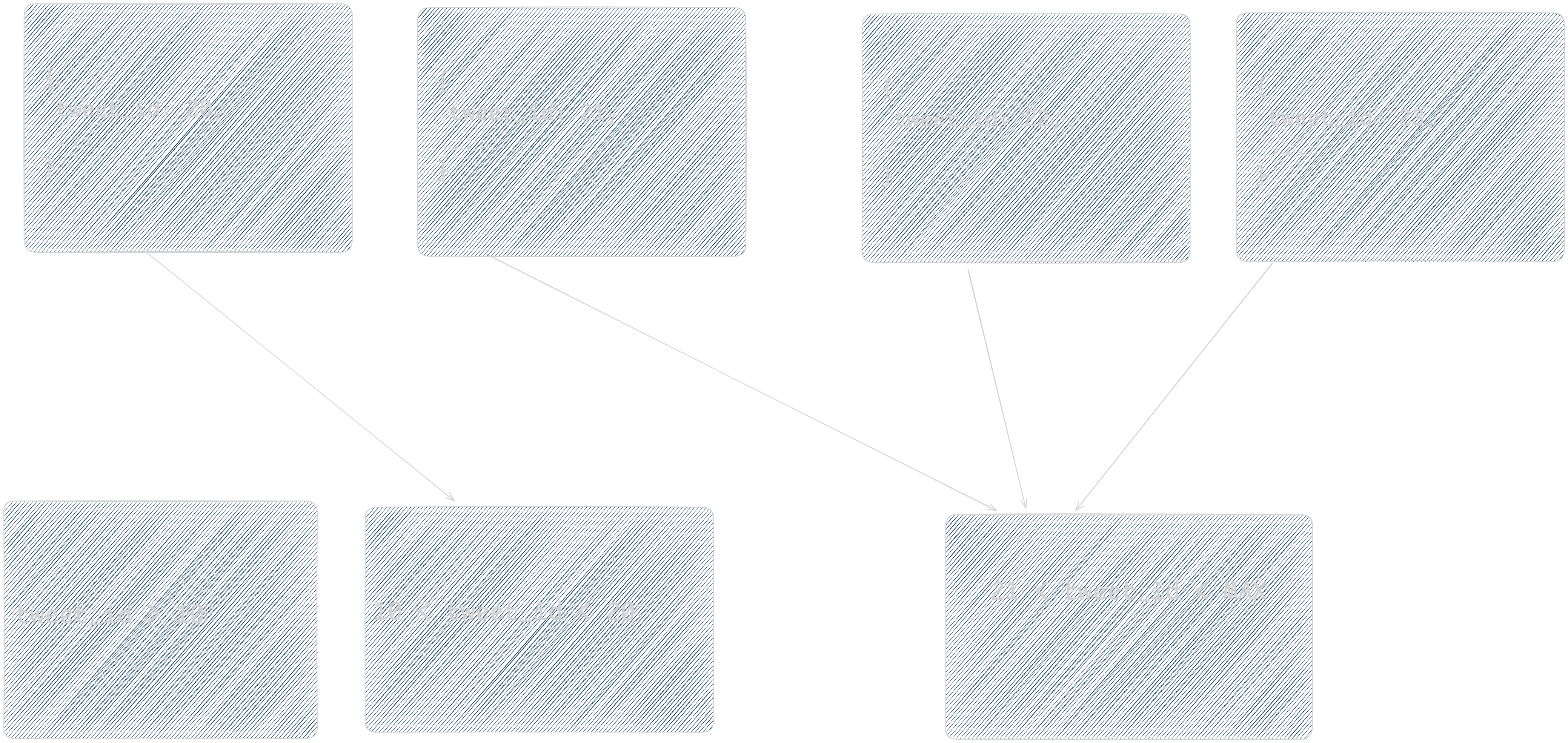
As evident in diagram above, tweet_id keeps increasing so after a certain limit all keys will end up in same shard skewing the distribution of data. Similarly if key had been monotonically decreasing, then majority of data would have ended up in first shard, making that shard bigger than others.
Based on Query Patterns
Shard key must be based on popular query patterns. If most of queries are utilising tweet_id, then its a good candidate to be a key. If our choice of shard key does not show up in majority of queries, then it will cause the router to query all the shards, then merge their result before returning it back to the app. Queries that involve multiple shards do not scale well when number of shards increase. Hence it is necessary for shard key to appear in maximum queries to reap the maximum benefit of sharding.
One of the most practical strategy to choose shard key is to analyze the common queries to the database.
Advanced Sharding - Hashed Sharding
While the previous approaches work well in many cases, they may still lead to uneven distribution of data. Hashed sharding provides a more consistent distribution of data. Shard key is passed through a hashing function whose output determines the destination shard. Shard key for hashed sharding should have good cardinality. Even monotonically increasing/decreasing keys which causes issues generally, can be used with hashed sharding because it distributes them among the shards instead of putting min/max ranges into a single shard.
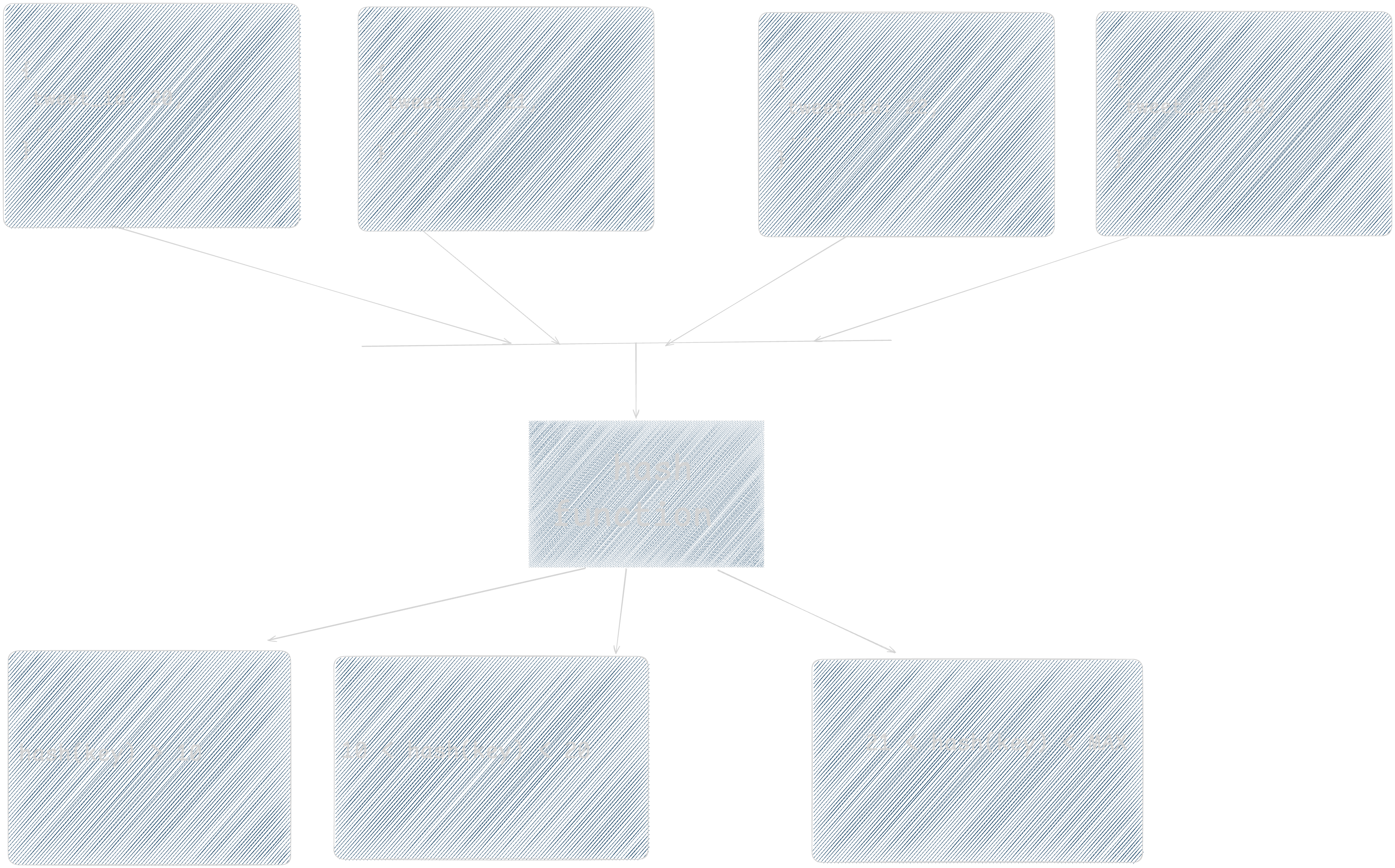
Equality queries have good performance because they can be resolved from a single shard. Consecutive data does not reside in the same shard anymore, which means that range queries will need to hit multiple shards.
Operational Aspects
Adding or removing shards from cluster
Sometimes our applications evolve in such a way that previous choice of shard key does not make sense anymore. So we need to reshard the data based on new key. Or we want to add more shards because current shards either have too much data on every machine. We may also face problem where data from one shard is requested more often compared to other shards.
In these cases, we always add a new machine to the cluster. Start replicating the data from existing machine. Once replication is done, then we update router to start sending requests to new shard also. Once there are no request for migrated data on older shard, then older shard deletes the data.
Similarly when we remove a machine from cluster, we first replicate its data to other shards. Once replication is done, then we update the router to stop accepting the requests. Once all in-flight requests are done, then we migrate the changes from those requests also to other shards. Now this shard can be removed safely.
Process of adding or removing shards is called rebalancing. Many modern database systems provide tools to automate this process.
Indexes
What happens to indexes in case of sharding? Well, each shard maintains its own indexes, and queries running on that shard make use of these indexes. Because these indexes are specific to the data residing on the shard, these are known as local indexes.
Conclusion
Sharding is a powerful technique to scale database horizontally. But it has its own set of challenges. And a good sharding strategy is needed to make full use of this technique.